
Java application written by Christof Prenninger, 1997-1998
adviser: DI Markus A. Hof
The Webcrawler can be used for crawling through a whole site on the Inter-/Intranet. You specify a start-URL and the Crawler follows all links found in that HTML page. This usually leads to more links which will be followed again, and so on. A site can be seen as a tree-structure, the root is the start-URL; all links in that root-HTML-page are direct sons of the root. Subsequent links are then sons of the previous sons.
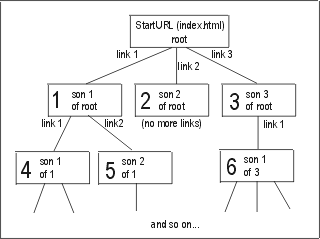
This program is a Java application (cannot be run as an applet), that implements the Model-View-Controller (MVC) pattern. The Crawler represents the model; this is the program that does all the work. So far I have implemented 2 different controllers and one view. One of the controllers is a simple StringFinder, the other a Grabber that downloads a whole site onto the local harddisk. The view shows the tree-structure of the specified site, plus an optional Tracer-Window that displays the internal work of the Crawler.
If you want to test this program, please download the following packages and unzip them to a new directory (e.g: C:/Program Files/Java/Webcrawler). Then view the readfirst.html file in that directory.
| crawl.zip | The main program and help-files. |
| classes.zip | The classes needed to run the program. |
| doc.zip | The documentation (HTML files) - optional. |

Please mail comments to Christof Prenninger and check out my homepage. Thanks!